
In early May, Google announced this year’s projects for the Google Summer of Code (GSoC). The project proposal of the Hellenic OCR Team was among the ones that were accepted for implementation! As a mentor to the project, I am glad to be able to contribute to this exciting endeavor.
Overall, Google funds 1273 student projects for 206 open source organizations who benefit from active involvement from new developers. In Greece, the Open Technologies Alliance participates in GSOC 2019 with 15 open source projects. Below, one may find interesting details to this project titled ‘Development of a Tool for Extracting Quantitative Text Profiles’.
‘Development of a Tool for Extracting Quantitative Text Profiles’
Brief Explanation
Quantitative text analysis is the basis of nearly every computational approach to text management and processing. All advanced Natural Language Processing (NLP) tasks including information retrieval, sentiment analysis, computational stylistics etc. involve the quantification of texts across a huge number of linguistic features and transform text into vectors. In many programming languages, e.g. R, Python, Java etc., there are numerous open source scripts, tools, packages and libraries that can transform texts to vectors of word frequencies, character and word n-gram frequencies, stylometric features etc. However, each of these tools covers only a restricted subset of the possible linguistic features. Moreover, the available tools are written in different languages and require considerable efforts to be combined so that the user can extract a unified file of results. Due to the fragmentary nature of the programing environments and the highly technical skills that are required to operate the tools and combine their results, they can’t be used by large communities of scientists with humanities and sociopolitical background. For the above reasons, we envisage the development of a user-friendly Graphical User Interface (GUI) based tool that shall provide integrated access to existing open NLP software. The new tool shall support the quantitative analysis of multilingual texts and produce quantitativetext profiles that can be used as input for further analysis, visualization, machine learning and other advanced computational processing. Such a tool does not exist to date and it will boost research in all scientific areas that require computational processing of large amounts of text.
Expected Results
The outcome of this project would be an open-source software with the following specifications:
- User-friendly GUI that can guide intuitively its users to select the features they want to count in their text collections
- Large set of linguistic features that include at least:
- Most frequent words of the texts analyzed
- User-specified word lists
- Word and Character n-grams of arbitrary length
- Different stylometric features such as vocabulary diversity indices, readability indices, quantitative linguistic indices
- UTF-8 support
- Corpus management features using text metadata
System architecture (proposed)
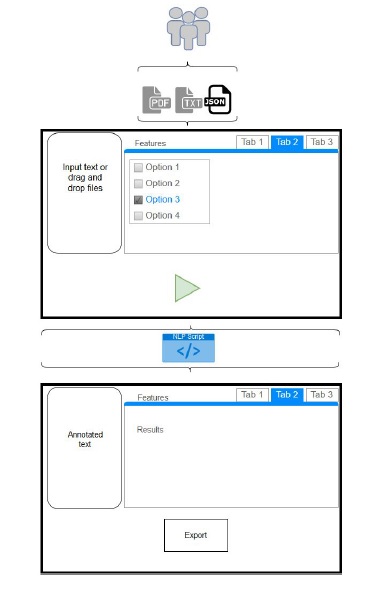
Project Timeline (to date)
Note: The timeline development must comply with the official GSoC timeline
- Community Bonding (May 6 – May 26)
- Meet with my mentors and discuss about the project’s architecture and implementation details.
- Get familiar with the tools and packages that are going to be used.
- Coding – 1st Phase (May 27 – June 28)
- Choose the necessary NLP packages and functions based on their usability and accuracy.
- Code the NLP scripts, using already implemented functions and ensure their compatibility.
- Design GUI’s layout and implement a simple, prototype GUI to test the above scripts.
- Coding – 2nd Phase (June 29 – July 26)
- Design the database.
- Develop a REST API for frontend – backend communication.
- Continue working on GUI.
- Coding – 3rd Phase (July 27 – August 26)
- Add export and visualization options.
- Test the application with real users and adapt to the feedback
Contributors
- Google Summer of Code 2019 Participant: Papantonakis Panagiotis (PanagiotisP)
- Mentor: Leventis Sotiris (sotirisleventis)
- Mentor: Mikros George (gmikros)
- Mentor: Fitsilis Fotis (fitsilisf)
- GitHub repo
***